I thought of experimenting a common question “Which is better in performance count(*) or count(1) or count(”) or count(column-name)?”. To test this and find the best performing count, I’ve done an experiment.
I created a table and inserted one million records and executed all the four statements at the same time. The create table and the insert statements are available in this article. Before executing the queries, I’ve selected the Include Actual Execution Plan in SQL Server Management Studio.
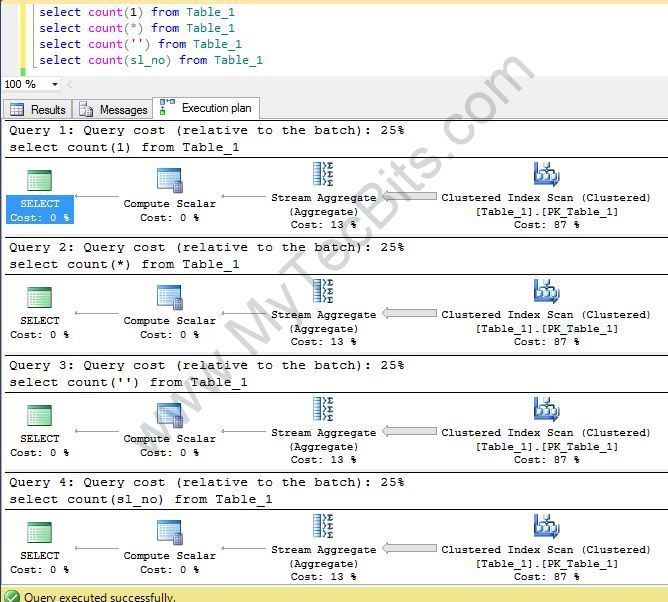
If you see the execution plan, all the statements has the same query cost. All the statements use the Stream Aggregate and Index Scan to the same proportion. So it’s clear that none of the count variations is better than the other. We can use any count to our convenience.